MPI+OpenMP: he-hy - Hello Hybrid! - pinning
 Recap from previous exercises:
Recap from previous exercises:
cd ~/HY-VSC/he-hy # change into your he-hy directory
Contents:
job_*.sh # job-scripts to run the provided tools, 2 x job_*_exercise.sh
*.[c|f90] # various codes (hello world & tests) - NO need to look into these!
vsc4/vsc4_slurm.out_* # vsc4 output files --> sorted (note: physical cores via modulo 48)
IN THE ONLINE COURSE he-hy shall be done in two parts:
first exercise = 1. + 2. + 3. + 4. (already done before)
second exercise = 5. + 6. + 7. (after the talk on pinning)
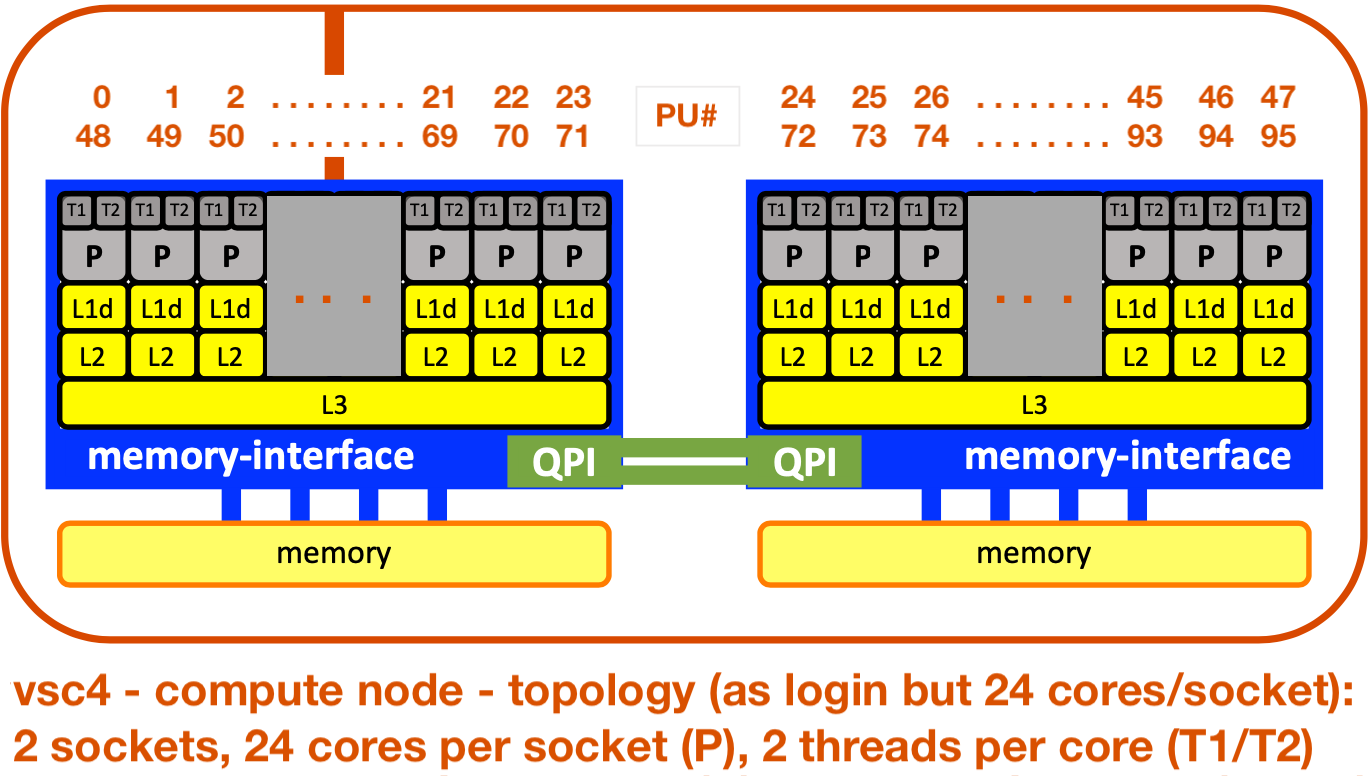 4. Recap from previous exercise: get to know the hardware
4. Recap from previous exercise: get to know the hardware
→ Find out about the hardware of compute nodes:
→ solution.out = vsc4/vsc4_slurm.out_check-hw_solution
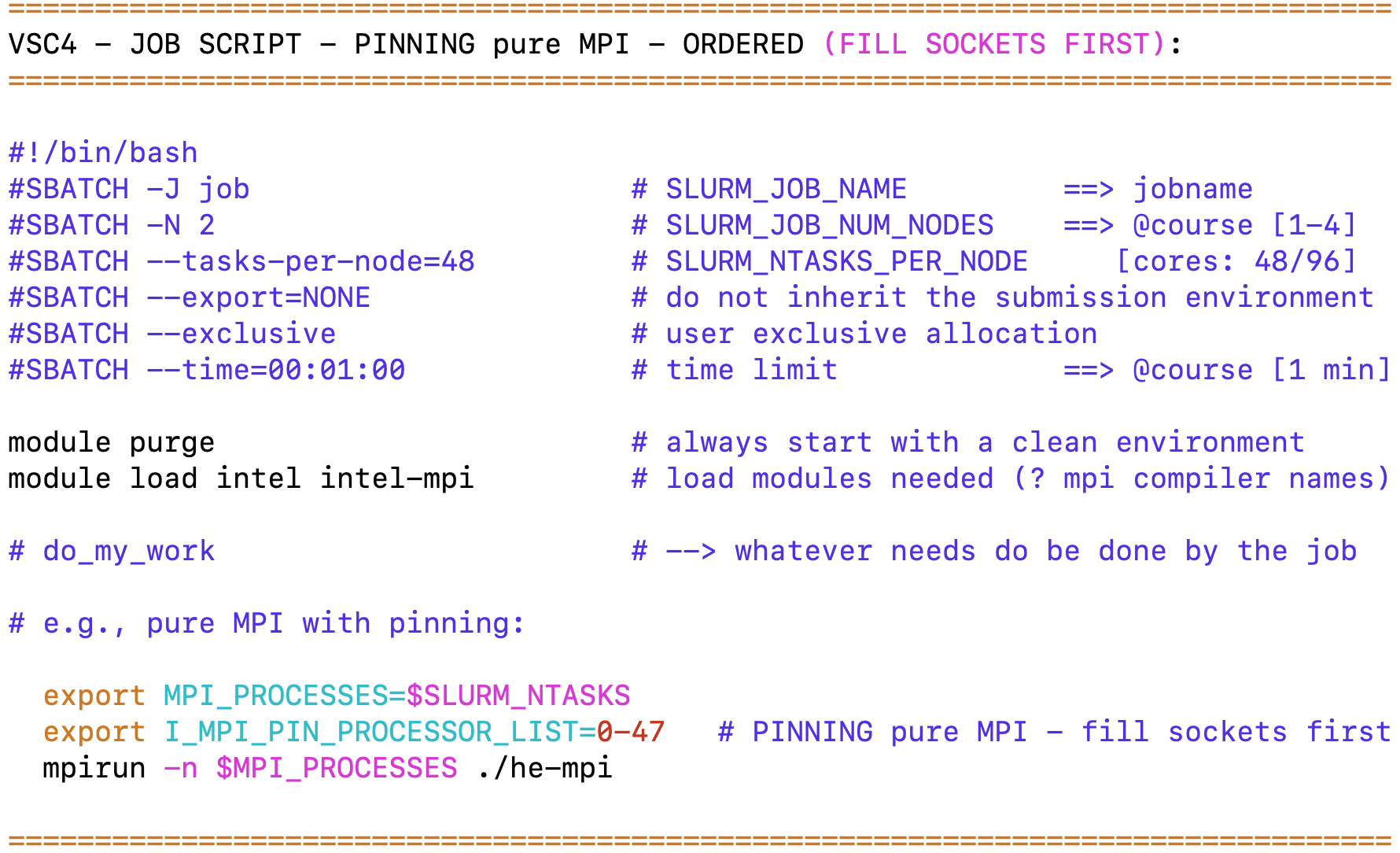
5. MPI-pure MPI: compile and run the MPI "Hello world!" program (pinning)
job_he-mpi_[default|ordered].sh, he-mpi.[c|f90], help_fortran_find_core_id.c
 compile he-mpi - either C or Fortran - precompiled version = C:
compile he-mpi - either C or Fortran - precompiled version = C:
C: mpiicc -o he-mpi he-mpi.c
Fortran: icc -c help_fortran_find_core_id.c
Fortran: mpiifort -o he-mpi he-mpi.f90 help_fortran_find_core_id.o
run he-mpi twice on login node with only 4 procs:
export I_MPI_FABRICS=shm # needed on (some) login nodes
mpirun -n 4 ./he-mpi | cut -c 1-54 # unsorted
mpirun -n 4 ./he-mpi | sort -n | cut -c 1-54 # sorted
? Why is the output (most of the time) unsorted ? ==> here (he-mpi) you can use: ... | sort -n
submit he-mpi to a compute node (mpirun):
sbatch job_he-mpi_default.sh # vsc4 --> okay (pinned to cores, but not to hw-thread; i.e., physical cores via modulo 48)
sbatch job_he-mpi_ordered.sh # vsc4 --> pinning to cores & hw-thread (T1); i.e., to physical cores 0-47 --> perfect
? Can you rely on the defaults for pinning ? ==> Always take care of & check correct pinning yourself !
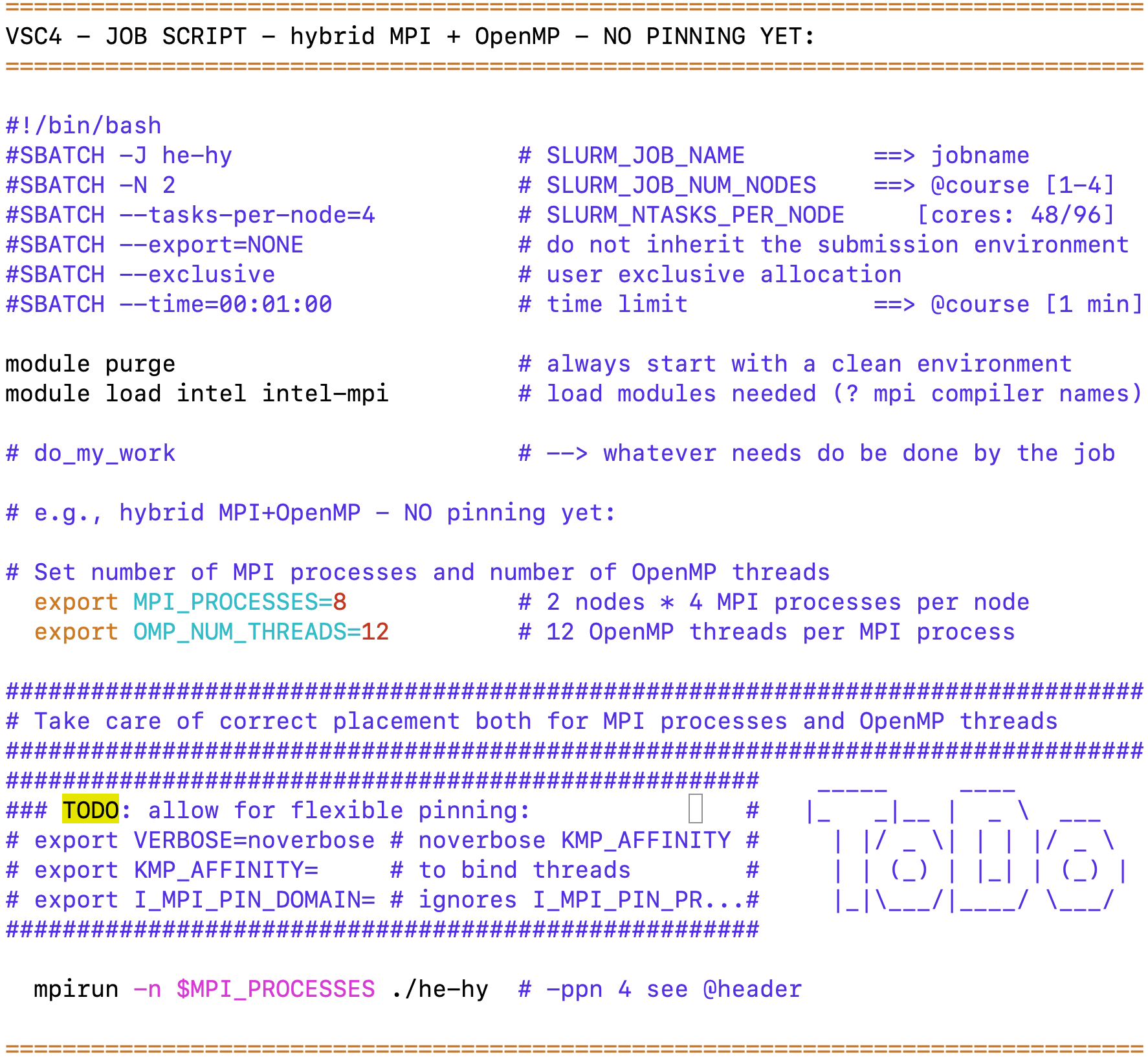
6. MPI+OpenMP: :TODO: compile and run the Hybrid "Hello world!" program
job_he-hy_exercise.sh, he-hy.[c|f90], help_fortran_find_core_id.c
compile he-hy - either C or Fortran - precompiled version = C:
C: mpiicc -qopenmp -o he-hy he-hy.c
Fortran: icc -c help_fortran_find_core_id.c
Fortran: mpiifort -qopenmp -o he-hy he-hy.f90 help_fortran_find_core_id.o
run he-hy twice on login node with only 4 procs & 4 threads:
export I_MPI_FABRICS=shm # needed on (some) login nodes
export OMP_NUM_THREADS=4
mpirun -n 4 ./he-hy | cut -c 1-80 # unsorted
mpirun -n 4 ./he-hy | sort -n | cut -c 1-80 # sorted
? Why is the output (most of the time) unsorted ? ==> here (he-hy) you can use: ... | sort -n
TODO:
→ Run he-hy on a compute node, i.e.: sbatch job_he-hy_exercise.sh
 → Find out what's the default pinning with mpirun !
→ Find out what's the default pinning with mpirun !
# vsc4 --> MPI procs okay, but OMP threads not bound --> we have to do better !
→ Look into: job_he-hy_exercise.sh
→ Do NOT YET do the pinning exercise, see below 7.
 ? Can you rely on the defaults for pinning ? ==> Always take care of & check correct pinning yourself !
? Can you rely on the defaults for pinning ? ==> Always take care of & check correct pinning yourself !
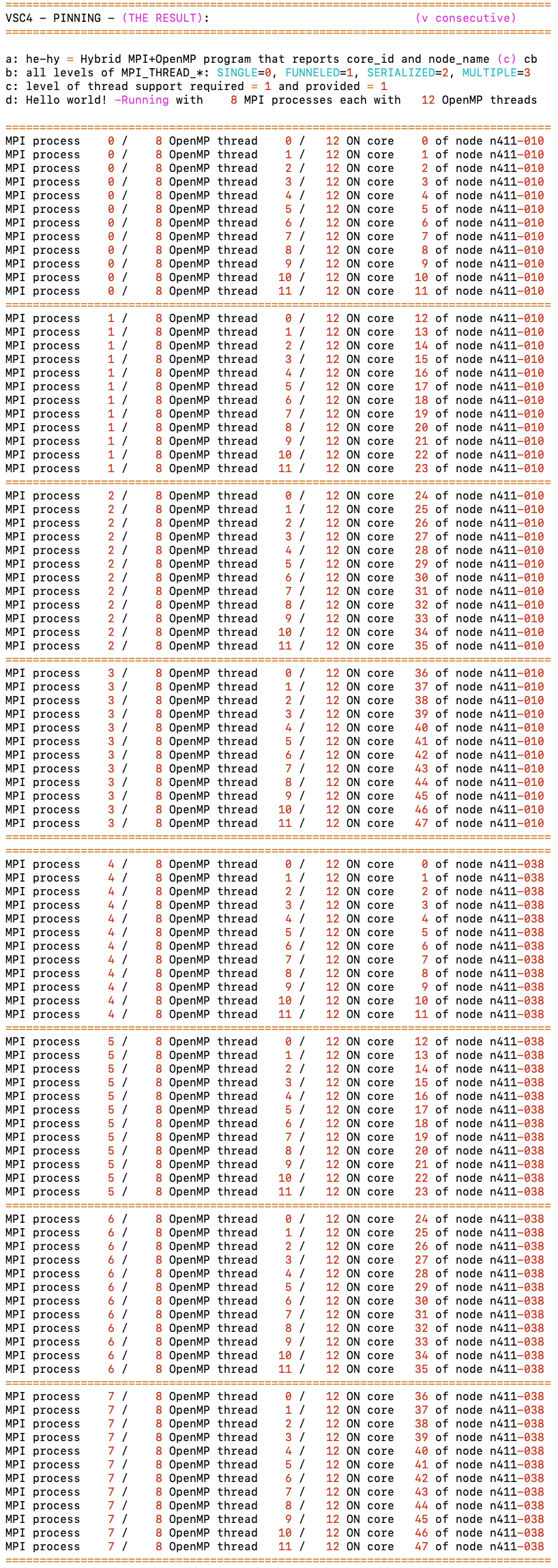
7. MPI+OpenMP: :TODO: how to do pinning
job_he-hy_[exercise|solution].sh, he-hy.[c|f90]
TODO (see below for info):
→ Do the pinning exercise in: job_he-hy_exercise.sh
→ one possible solution = job_he-hy_solution.sh
# vsc4 --> pinning of MPI procs & OMP threads done perfectly
PINNING: (→ see also slides ##-##)
Pinning depends on:
| batch system | [SLURM*] | \ |
|---|---|---|
| MPI library | [Intel*] | | interaction between these ! |
| startup | [mpirun*|srun] | / |
Always check your pinning !
→ job_he-hy...sh (he-hy.[c|f90] prints core_id)
→ print core_id in your application (see he-hy.*)
→ turn on debugging info & verbose output in job
→ monitor your job → login to nodes: top [1 q]
Intel → PINNING is done via environment variables (valid for Intel-only!):
pure MPI: I_MPI_PIN_PROCESSOR_LIST=<proclist> (other possiblities see Web)
MPI+OpenMP: I_MPI_PIN_DOMAIN (3 options) + KMP_AFFINITY
I_MPI_PIN_DOMAIN=core|socket|numa|node|cache|...
I_MPI_PIN_DOMAIN=omp|<n>|auto[:compact|scatter|platform]
omp - number of logical cores = OMP_NUM_THREADS
I_MPI_PIN_DOMAIN=[m_1,.....m_n] hexadecimal bit mask, [] included!
OpenMP: KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
modifier type (required)
granularity=fine|thread|core|tile compact
proclist={<proc-list>} balanced
[no]respect (an OS affinity mask) scatter
[no]verbose explicit (no permute,offset)
[no]warnings disabled (no permute,offset)
none (no permute,offset)
default: noverbose,respect,granularity=core,none[,0,0]
Debug: KMP_AFFINITY=verbose
I_MPI_DEBUG=4
Example from slide ## (last pinning example in the slides):
1 MPI process per socket, 24 cores per socket, 2 sockets per node:
export OMP_NUM_THREADS=24
export KMP_AFFINITY=scatter
export I_MPI_PIN_DOMAIN=socket
mpirun -ppn 2 -np # ./<exe>
see: job_he-hy_test-1ps.sh + slurm.out_he-hy_mpirun_test-1ps (note: physical cores via modulo 48)