MPI+OpenMP: jacobi - hybrid through OpenMP parallelization

Prepare for these Exercises:
cd ~/HY-VSC/jacobi/C-hyb-jacobi # change into your C directory .OR. …
cd ~/HY-VSC/jacobi/F-hyb-jacobi # … .OR. into your Fortran directory
Contents:
1. BASIC EXERCISE → Everybody should finish the basic exercise!
2. INTERLUDE: ROOFLINE MODEL AND LIGHT-SPEED PERFORMANCE → Will be explained!
3. ADVANCED EXERCISE → If your exercise group is really fast, you might try it.
4. EXERCISE ON OVERLAPPING COMMUNICATION AND COMPUTATION → Tomorrow!
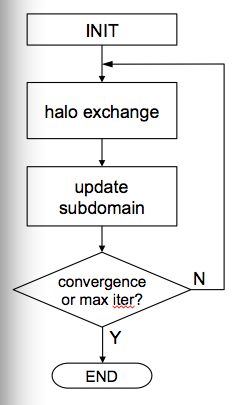
Jacobi Exercises: (→ see also slides ##-##)
♦ This is a 2D Jacobi solver (5 point stencil) with a 1D domain decomposition and halo exchange.
♦ The given code is MPI-only.
♦ You can build it with: make (take a look at the Makefile)
♦ Edit the job-submission file: vi job.sh
♦ Run it with: sbatch job.sh
♦ Solutions are provided in the directory: solution/
1. BASIC EXERCISE (see step-by-step below)
- Parallelize the code with OpenMP to get a hybrid MPI+OpenMP code.
- Run it effectively on the given hardware.
- Learn how to take control of affinity with MPI and especially with MPI+OpenMP.
 NOTES:
NOTES:
- The code is strongly memory bound at the problem size set in the input file.
- Always run multiple times and observe run-to-run performance variations.
- If you know how, try to calculate the maximum possible performance (ROOFLINE).
STEP-BY-STEP:
→ Run the MPI-only code with 1,2,3,4,.... processes (in the course you may use up to 4 nodes),
and observe the achieved performance behavior.
→ Learn how to take control of affinity with MPI.
 → Parallelize the appropriate loops with OpenMP (see Documentation links below).
→ Parallelize the appropriate loops with OpenMP (see Documentation links below).
→ Run with OpenMP and only 1 MPI process ("OpenMP-only") on 1,2,3,4,...,all cores of 1 node,
and compare to the MPI-only run.
→ Run hybrid variants with different MPI vs. OpenMP ratios.
What's the best performance you can get with using all cores on 4 nodes?
!!! Does the OpenMP/hybrid code perform as well as the MPI-only code?
→ If it doesn't, fix it!
 RECAP - you might want to look into the slides or documentation:
RECAP - you might want to look into the slides or documentation:
→ Memory placement - First touch! (→ see also slides ##-##)
→ PINNING = end of the previous exercises ( → see also slides ##-##)
→ Documentation: OpenMP LIKWID MPI
2. INTERLUDE: ROOFLINE MODEL AND LIGHT-SPEED PERFORMANCE
→ see images
3. ADVANCED EXERCISE → REDUCE THE DATA TRAFFIC
→ Think about how you could improve the performance of the code...
→ Have a look on how the halo communication ist done.
==> halo communication is overlapped with inner update (U_old = U)
→ Why is non-blocking MPI communication used here?
→ Does it make sense to overlap halo communication with inner update?
→ If not, do you still need the non-blocking version of the MPI routines? Why? Why not?
→ Is there a way to increase the computational intensity of the code (reduce data traffic)?
4. EXERCISE ON OVERLAPPING COMMUNICATION AND COMPUTATION
Finally, let's overlap communication and computation...
1. substitute the omp for by a taskloop:
parallel{ single{ taskloop for{<compute stencil and update>}}}
--> this allows you to see the overhead of taskloop
--> maybe you need a larger problem size to work on (input)
--> grainsize might help...
2. overlapping communication and computation:
parallel{ single{ task{halo exchange + halo rows} taskloop{internal computation} }}